Welcome! I am Tracy Keys, and you can find me on Instagram @benjibex.
This blog is all about my passion for media, entertainment, fashion, society and the environment and how data science can be used as a tool in communication, activism, politics and marketing. This site is a showcase for my creations as I develop from data lover to communication data science professional.
I’m just getting this new blog going, so right now it’s mostly the transfer of my academic papers and blogs into one place. Ultimately, I want to express myself with data science and explore society through this medium: data science is also an art and highly creative as well as being analytical. The work to date comes from my journey of exploration and learning, but bringing it to life with my tone of voice will no doubt be a lifelong addiction. Stay tuned for more blog entries. Subscribe below to get notified when I post new updates.
Cover image is by Charlie Egalie Tjapaltjarri (Australian, b. ca. 1940–2002) Possum Dreaming , 1994
In my last blog post I wrote about the Pintupi community from Australia’s Outback that is the subject of an Australian Broadcasting Commission (ABC) video from 1988. In this post I will delve deeper into this community around that time to discuss concepts of racialized organizations (Ray), appropriation of technology (Eglash) and how the label of “innovation” is bestowed through social and political processes rather than being an objective quality of something or someone (Irani). I focus on the innovation of Pintupi Aboriginal Art and the communication processes and networks that developed around it to move it from the category of cultural artefact to fine contemporary Art. I will review the winners and losers from this innovation, and finally bring the discussion back to the original video. My information is of course second hand, based mostly on the accounts of anthropologists Myers and Morphy who wrote about Pintupi artists.
The Pintupi People
As an Australian, I was very interested in the video about the Center for Appropriate Technology and its work with the Pintupi in Australia’s remote outback. As noted in my last blog post, the video failed to mention any innovations of the local people to solve their own problems. The video producers appeared to have a patronizing attitude towards the Pintupi, which is unsurprising given that attitude has been a persistent feature of Aboriginal Affairs since Australia was invaded and settled in 1788 by the British.
The name of the tribe was very familiar to me because their community was a focal point for Aboriginal land rights protests in the latter half of the twentieth century and their people were involved in either protesting or celebrating the bicentenary of Australian occupation in 1988. The Pintupi people (so named because the original camp was called Papunya) had been moved off their ancestral lands to Papunya, their traditions destroyed by a government policy of “assimilation” and were really devastated as a community. The conditions in the Papunya camp were at times atrocious and people were despondent, many addicted to drugs and alcohol. See the Appendix for more background.
Art in Pintupi
There was another big reason for my knowing the name Pintupi: the Pintupi were renowned for being the catalyst the Central Desert art movement whose art were the famous “dot paintings” that have been shown all over the world. I learned about it in high school.
Arts and crafts were considered by white officials a way of keeping the Aboriginal people occupied and lifting their spirits. Aboriginal people were introduced to painting acrylic on boards through white people, but long before this, ochre painting was a key part of their traditions, either on bodies or caves and in rituals and ceremonies. Painting was very sacred, and traditionally only mature initiated males could be involved with it.
The Pintupi people began painting in earnest in the early seventies, and you can read more in Appendix 1 if interested. It was very surprising to me that the video producers failed to mention how culturally important this community was because they really were innovators in the art field.
Pintupi Art Innovation
Once introduced to painting on canvas, the Pintupi artists became voracious painters. Like Caribbean disc jockeys in New York, they appropriated the painting “technology” and innovated wildly, moving their style away from realism to the iconic abstract expressionist “dot paintings” we know today (Eglash; Myers; Morphy). With the support of art advisor Bardon and his successors and the government funded Aboriginal Arts Board, the artists established the Papunya Tula Company as a cooperative owned by the artists themselves, to promote their art collectively (Myers). Bardon began to build a market for the artists, partly in order to keep them supplied with canvases as they were producing paintings at such a rate, but also because the art advisor was also an anthropologist who believed in the power and value of these paintings too.
Aboriginal Valuation of the Art
The artists were very clear, these paintings were showing their Dreaming, their history and connection to Country, and they were extremely valuable. So valueable in fact that only those mature initiated men whose ancestors came from that part of the land were able to paint its Dreamtime stories and history, and only mature initiated men could view the paintings at all, either when they were in progress or completed (Myers; Myers; Keller).
They owned these stories like property and producing paintings of Dreamtime and selling them was giving them to others. As a result, the artists expected a lot in exchange for what they felt was essentially giving away their land and their legacy to white people (Myers). In this way, the painting was a way for them to assert ownership of their traditional lands that white people had taken.
Western Valuation of the Art
However, the art market did not have the same sense of appreciation for Pintupi art, at least not in the beginning. The art market is a capitalist, Western institution, and I would argue a racialized one at that. The racialized art market organizations were ill equipped to connect the resources of cosmopolitan buyers and galleries to black artists in a remote camp in outback Australia.
The art advisors had to mediate between the expectant artists and an unresponsive art market. Myers, an anthropologist from the US saw firsthand that they faced a huge problem of translation because the art style was so new, and it broke the traditional categories of the art market and the Western view of aesthetics.
Myers writes about the art-culture system in the art market, which is the social and cultural system that categorizes products and assesses their value in line with this categorization. Myers and Morphy both explain that this system is firmly grounded in Western culture and values. As Irani describes innovation in India, Myer, Keller and Morphy recognize this categorization is a social and cultural discursive process rather than inherent characteristics of the art piece, and it was systematically inclined to ignore the innovations of Aboriginal art.
Underlying definitions of market value in the art-culture system is the capitalist schema, whereby a work only has value in exchange. To give the Pintupi art value in our capitalist ideology, it needs to be commoditized, ignoring value in use in order to be valued in terms of what it will sell for on an open market (Ray).
On the art side of the art-culture system, this category tends to comprise of urban and cosmopolitan works: generally White Global North products (Myers). The value of fine art depends on how innovative it is, the difference it has to other paintings produced before it, the painter’s skills and the work’s aesthetic value, based on Western definitions of aesthetics and evaluations of prior art (Myers; Morphy). This definition sounds to me like Jordan’s definition of hacking and hackers because the value of fine art depends on how good a hack it is, as assessed by the art world, valuers, art experts and other artists. (As an aside: the value is assessed by insiders, you could almost call it insider trading.) A valuable piece of fine art is a material practice that creates a difference, demonstrates mastery, impresses the artist peer group and often makes a political statement (Jordan).
If not considered fine art, their innovative art would be relegated to the category of cultural artefact. The category of “culture” tends to be reserved for remote, primitive, traditional, anthropologic products produced by people of color. Myers notes that Pintupi works needed a written description to go alongside them, and as a result are categorized in the culture category because they have more of an anthropological value.
The value of a cultural artefact is determined by its age and the extent to which is was “pre-contact” and “authentic” and free of Western influence (Myers). However, the materials (acrylic paints and canvas or boards) of Pintupi art were modern, and the techniques were all learned recently by the artists, so the works were neither old nor “untouched” techniques. Therefore, their value in the culture category was low, but they were highly innovative! Because the system was underpinned by the capitalist schema which generally gave power and value to white people, the art advisors and the Aboriginal Art Board knew they had to push to change the categorization to ensure the Pintupi art was recognized as fine art in order to achieve the kind of value in exchange the artists expected.
Recognition as Fine Art
At this time, in the early seventies, it was impossible for a remote community of art outsiders who had only recently been introduced to the cash system to change this categorization. For them to generate value in exchange, they needed insiders to guide, mentor, and champion their art.
Vivien Johnson, the then wife of artist Tim Johnson and an art insider, long maintained that Pintupi Aboriginal Art should be categorized as contemporary Australian fine art in order for it to achieve the valuation and recognition it deserved (Myers).
Morphy also argues that the category of fine art needs to be more multicultural and incorporate more points of view than the Western one. The Aboriginal artists of Papunya Tula broke the “culture” mold, producing art that was innovative, masterful, skillful, and full of iconography, meaning, aesthetic beauty and political statements. Why should it not be considered fine art?
This is very similar thinking about traditional people’s innovation in India like the lota, relegating it to jugaad and therefore traditional and useful and quaint, but not innovative.
The macro level conditions were however ideal for this change to happen, and there were many supporters of these artists that helped them navigate the racialized organizations and put in the work to change the processes of art valuation.
Communication networks supporting the Art
Conditions at the State and macro level were present for a well-resourced and well-connected network to grow around the objective of supporting Aboriginal fine art.
Firstly, the Australian Government changed its position on Aboriginal Affairs in the early seventies from a strategy of assimilation to one of self-determination, and the government held the view that producing Aboriginal art would be instrumental in achieving self-reliance. Idealistically, this was because an indigenous art movement would help Aboriginal people feel proud to express themselves as Indigenous Australians, and they could rally behind their culture and traditions. More cynically, this was a branding exercise: aboriginal art could be an example of how Australia was improving race relations, and Pintupi art could bring more tourism to Australia’s outback (Myers).
In addition, the national government took over management of the Aboriginal people and their camps, meaning that they could effectively operate the camps to put this “self-determination” strategy into effect (Commonwealth Parliament House).
As explained by Ray, a change in policy in a racialized organization does not guarantee a change in the reality for the subordinate people, in fact it can make racial inequality even worse because people take their eye off the ball. However, the Whitlam government in 1972 put in place and funded organizations to implement their policy: the Aboriginal Art Board (AAB), the Australian Council for the Arts and the Department of Aboriginal Affairs (Myers; Commonwealth Parliament House). These institutions were able to use their knowledge, communication channels and networks to connect the Pintupi to the art world’s resources.
These organizations set up prestigious art prizes and sought out corporate sponsors. These sophisticated cultural events were exactly what the art market and corporate sponsors want to experience, so they feel they can do something for Indigenous Australia without ever having to put their champagne down. Winning a national prize like the NATSIAA gave artists direct exposure to the art market and resulted in overwhelming demand for their work (Gibson; Keller).
The art movement also benefited from the appointment of key individuals to positions of power such as the AAB’s first Chairperson, Bob Edwards, who was a skilled administrator who ensured strong and effective Papunya and indigenous representation and decision making on the Board. Due to his passion and skill, he was able to negotiate the art world, and get the work exhibited in local and overseas art galleries. Edwards was personable and well-connected and could operate to connect the local indigenous world to the international art scene as a bridge between these networks. His work helped create bridging social and cultural capital
There were also the art advisors, Bardon and then Fannin and many others afterwards, based at Papunya who liaised between the fledgling markets, the AAC, the galleries and the artists. These advisors nurtured the communities creativity and encouraged and supported artists entries into art competitions (Keller; Gibson).
Keller quotes such an advisor who was working with women fiber artists in South Australia, describing her role ((Keller page 8):
“I just had a feeling…that she had such a sense for sculpture and architecture…and ways of arranging space. …I remember just saying to her, keep making anything you want, just whatever you think of. Let’s make it and leave the rest to me. …everybody was thinking I was crazy. I remember, as I was loading it on the plane [which was very difficult] … But we did get it on the plane, and it won in the Art Award.’
(Moon 2003, pers. com., 8th October)
These advisors worked the established white world processes of communication, capital raising and networking to drum up the cash to purchase art supplies for exhibitions. They wrote documentation for the art works in English to prove their “authenticity” and “uniqueness” which they felt was vital to supporting their value and making them salable in the art market. They were bilingual: figuratively, and literally translating the value of the Papunya Tula Company’s body of work into international fine art value.
Key individuals like Edwards and the AAB and other organizations did the marketing, organized exhibitions, sought out patrons, lectured at universities, made decisions, sought government grants and all the work to ensure the art movement was funded. Of course, there were always complaints from the art advisors that more funding was required. They felt they needed more advisors because the painters were so prolific: the art advisors couldn’t keep up with the documentation needed so not all art was salable, which was a missed market opportunity (Myers).
There was resistance to and undermining of these policies by the local management hired by the State governments (who had lost control of Aboriginal Affairs in favor of the national government). The local authorities were against indigenous art because they felt it was encouraging insubordination; it encouraged protests (albeit in artistic form), and pride in tradition and in being Aboriginal, which went against the previous policy (and current State policy) of assimilation (Myers). Many other white people were against what the art represented, Aboriginal land rights and protests against the devastation wrought by the British colonization of their home.
The art advisors had a very precarious position trying to encourage the work of the artists whilst being scrutinized by the local authorities, essentially feeling like “gun-runners” trafficking illegal art (Myers). There was a lot of burn out by the people filling these positions, but the role continued to be filled whilst the art kept coming. In this way, the art advisors helped navigate the pitfalls that could not have been avoided without a white “benefactor”, which is a hallmark of a racialized organization as described by Ray.
With all these resources and skilled operators working to build communication networks to promote the ever growing, high quality art production of the Papunya Tula Company, the art was able to reach the international art market and eventually be valued in monetary terms in equal terms as the value placed on it by the artists themselves.
By the year 2000, when Sydney Australia held the Summer Olympic Games, the Art Gallery of NSW held a retrospective of Papunya Tula Company’s artists and work, called Genesis and Genius (Myers; AGNSW). This exhibition showcased the work of the artists to all the international Olympic visitors, recognizing the Pintupi artists as being the genesis for Western Desert art movement.
Winners and Losers
As explained by authors Berkun and Godin, it is myth that all innovation is good for society (Berkun; Godin). There are winners and losers even from the Papunya Tula Company innovating to produce Aboriginal fine art, as it becomes commodified on the international art market.
Firstly, there is the question of exploitation of the Pintupi and other indigenous artists. The artists painted their culture and their personal Dreaming, selling it for a few hundred dollars. Westerners then “made” the market for the product, gaining supernormal profits from its resale.
Myers quotes Anne-Marie Willis in his book who writes about this commodification of art like Irani and Lindtner do about Indian and Chinese innovation respectively:
“The meanings are not buried in the works, they are actively constructed through the agencies of art criticism, journalism, context of appearance. . . .The paintings do not produce useful knowledge for those who view and buy them; for the purchaser they are tantalizing tokens of Otherness, an Otherness which cannot threaten, and is in a subordinate position because of its dependence on the system of commodification as it operates within a neo-colonial context. “
(Myers page 315)
The artists themselves generally don’t financially benefit from the astronomical resale prices their art received (Myers). They are still living in poor conditions, in communities dependent on welfare. The capitalist myth of the “trickle-down effect” has not brought any lasting benefit there.
Indeed, many like Myers see the influence of the commodification of the art as corrupting, but to me it is just the capitalist market doing its work as it does on all people. The Pintupi people knew the value of their paintings, and they knew they were being exploited by not receiving fair compensation for their work, and this often made them very angry (Myers). Over time they are bound to learn the value of money.
As the government in recent years has stepped back to allow the Aboriginal art industry to be self-regulating, there was a flood of inauthentic and low-quality art works on the market (Myers; Gibson). This lead to stratification of the art into a fine art and a tourist quality, and to the pursuit of art from particular artists rather than from a community, which then stratifies the community into winners and losers. Many artists sell their work to the highest bidder rather than honoring exclusive deals they have signed, or the agreements with their cooperative that funded their career, and white folk fight over who has the closest relationship with the artists (Myers).
Another losing group were communities in other parts of Australia who felt that resources were unfairly prioritized towards the Central Desert artists because they are the ones with the biggest name overseas (Gibson). In fact, more urbanized Aboriginal communities have been compared to Central Desert peoples and judged lacking because they had “no visible culture to speak of” (Gibson). This of course is a terrible insult and certainly the Pintupi are not to blame for this, but it has been noted.
Still, there have been incredible benefits flowing from this innovation to move Papunya Tula art into the fine art world.
The Pintupi people and other Aboriginal people have benefited from the art facilitating a connection with Country and their traditions and their identity as Indigenous Australians. The international recognition of their work has led to a sense of pride that has benefited Aboriginal people across Australia, and according to Myers participation of urban and remote Aboriginal people in the running of Aboriginal Art Board, visits to Country to share ideas, art workshops and other programs have brought different tribes closer together.
Indigenous people in other parts of the country have taken the example of the Pintupi and revived traditional skills and culture that was almost lost, such as fiber weaving in South Australia (Keller) and line painting and carving in New South Wales (Gibson).
Indeed, the women fiber artists have innovated themselves and “gone sculptural”, progressing from baskets and other woven fiber implements to sculpture and in the same way moved from culture to fine art. As an aside, women were initially not even allowed in Aboriginal culture to see painting happening, let alone paint themselves. They appropriated painting “technology” by turning to fiber art, which did not have these same restrictions to express themselves artistically (Eglash; Keller).
Lastly, the artists found a way through their art to bring their Dreaming to the forefront of Australian culture. Every school child who studies art now knows of the Pintupi camp and what the people did there. Aboriginal art is now taught in every fine arts program in the country due to their influence and achievements. This has enriched Australian culture immensely.
The Pintupi are not as portrayed in the video passive and neglected consumers of western technology, but people who work creatively to honor their traditions, keep their culture alive and win back their lands and dignity. It is this, their spirit of innovation, so grounded in tradition and full of respect for Country that was missing from that 1988 video about appropriate technology. Hopefully, this paper has righted that omission.
Gibson, Lorraine. “’We Don’t Do Dots–Ours Is Lines’–Asserting a Barkindji Style.(Report).” Oceania, vol. 78, no. 3, University of Sydney, 2008, p. 280.
Godin, Benoît. “Innovation: A Conceptual History of an Anonymous Concept.” Edward Elgar Publishing, vol. 25, no. 32, 2017, p. 36.
Irani, Lilly. Chasing Innovation Making Entrepreneurial Citizens in Modern India. eScholarship, 2019.
Jordan, Tim. Hacking: Digital Media and Technological Determinism. Polity, 2008.
Keller, Christiane. “From Baskets to Bodies: Innovation Within Aboriginal Fibre Practice.” Craft + Design Enquiry, vol. 2, 2010, p. np.
Ray, Victor. “A Theory of Racialized Organizations.” American Sociological Review, vol. 84, no. 1, SAGE Publications, 2019, pp. 26–53, doi:10.1177/0003122418822335.
Appendix 1 Background
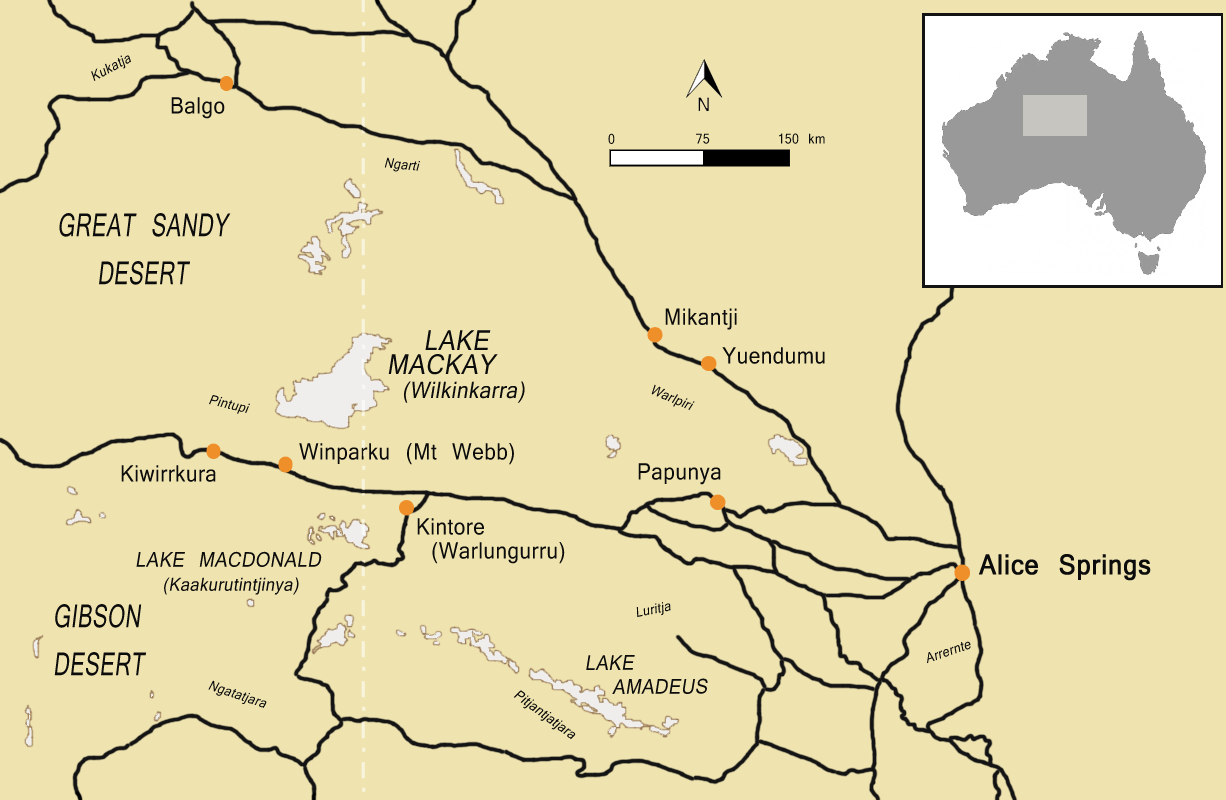
The video we reviewed for Module 4 was shot in 1988, the year of Australia’s bicentenary. Sensitivity to race relations nationally was then at an all-time high because 1988 marked 200 years of occupation and yet indigenous native title and land rights were still being denied in Australian courts, the aboriginal people were still dying in great numbers in police custody, people were only just being returned to their ancestral lands (like Kintore), and no one had made reparations for the decades old policies of forced separation of indigenous children from their parents. Given this context, the video does seem quite tone deaf, even for 1988.
The Pintupi are known in Australia, as they were back when this video was produced. As mentioned by the narrator, the Pintupi had been forcibly removed from their traditional lands and were settled in Papunya, but at the time of the video had returned to their homelands in Kintore (Emberson). In addition, some of their members were the last people in Australia to live a traditional nomadic life (the Pintupi Nine joined the community from the Gibson Desert in 1984) and that brought the community some renown. This community was a focus of land rights demonstrations, and the scene of rock music videos and events held to protest the treatment of Aboriginal people in Australia.
Protests were based there because Aboriginal settlements in remote parts of Australia like Papunya are very basic, and at times the conditions were horrendous and residents died from treatable conditions (Cirino; Myers). The Superintendent and supervisors of Papunya throughout the fifties and sixties were responsible for “assimilating” the aboriginal people into white culture as was the government strategy of the day, which basically meant destroying their culture and free will (Myers; Commonwealth Parliament House). The indigenous people suffered boredom, despondency, violence, and despair from the loss of their lands and heritage, and they were dependent on the State for everything (Myers; Gibson).
Alongside of all this political and cultural renown, the Pintupi were known for their incredible skills as contemporary Australian artists. Art and painting were a vital part of the Pintupi communities’ lives, and a source of pride and community in the camp. Painting was handed down from their ancestors for rituals and ceremonies using body painting and cave painting.
In addition, like many Aboriginal communities, Pintupi people produced and sold arts and crafts, souvenirs and trinkets to tourists or to other businesses to make money (Keller; Gibson; Myers). Earnings were very modest, providing a small supplement to their welfare payments. The welfare payments themselves were characterized as a training and development allowance because producing craft was considered “work” by the government and by the Pintupi people, and the government believed it was a way to deal with “the Aboriginal Problem” and keep boredom and despondency at bay (Myers).
In the 1940s, Albert Namatjira who lived near Papunya began painting to great acclaim in a realistic modern style, and that style was how Pintupi people initially started to paint in Papunya. Myers writes that “painting boards” was introduced there by an art advisor and teacher called Geoffrey Bardon in the camps in the early 70s as a form of arts and craft, but according to one of the most famous painters from there, Clifford Possum Tjapiljarri, he received his first set of acrylic paints from Albert Namatjira himself (Myers; Morphy; Keller; Owen).
In this post, I am looking at technological innovation from a critical perspective, covering appropriating technology, hacking and the process by which the name “innovation” is bestowed, or not, using a video from 1988 as provocation.
In 1988, the national Australian public broadcaster ABC and journalist Jill Emberson produced a short 7 minute story on their Quantum Science TV program about Dr Bruce Walker (Emberson) and “appropriate technology”. Dr Walker founded the Center for Appropriate Technology in Alice Springs, in the Australian outback, to improve the lives of Australia’s first people. The story shows his work in one of the remotest communities in Australia: the Pintupi people in Kintore, about 300 miles out of Alice Springs, which is very, very remote!
The philosophy of appropriate technology “looks for the real functions technology should serve, without any assumptions.” This means Dr Walker makes decisions differently to those made when designing technology for the urban environment. Throughout the video, Dr Walker explains how the environment in these remote parts of Australia is very harsh: extreme heat and cold, monsoons, dust, wind, and without reliable sources of water and power, if any at all. This means that technology designed for urban environments does not last out there, and sometimes would not work at all. Emberson the journalist says the standard explanation for why it does not last is to blame the people, saying the technology is misused. However, Dr Walker points out these outsiders from the big cities (Sydney and Melbourne) do not understand the harsh conditions of the outback and tend to patronize the indigenous people. Dr Walker suggests instead of wasting time and money trying to teach people how to use these technologies “properly”, they should ask why they are using it the wrong way in the first place.
Dr Walker needed to make decisions about what materials to use, and how things can be powered, operated, maintained, and repaired, appropriate to the environment and community they will be used in. This is very different to the environment and communities they were designed for originally, the urban environment.
The video talks about washing machines as an example. The narrator points out that Aboriginal people use a lot of blankets, to keep warm in the desert and as ground sheets or covers, and no western washing machine can fit them, let alone handle cleaning them. In addition, the washing machine made in the city with plastic parts and needing electricity will wear out too quickly in the arid desert.
The video then shows Dr Walker’s wonderful design of a mechanical washing machine, one that works well in the harsh outside conditions of the desert, does not need electricity, is large enough to handle blankets and uses basic metal parts that the Pintupi people can repair. These are the essential considerations for Dr Walker when making design decisions for engineering appropriate technology for remote communities in Australia. The “chip heater” (sorry not sure if thats what it is actually called, couldnt quite catch it in the video) is also given as an illustration of appropriate technology: re-purposed gas cylinders that Dr Walker’s team trains community members to repair, and which utilizes the local people’s excellent skills at fire-building.
One final example is the mobility device for those differently abled in the community, which was low to the ground so they could sit with everyone else, meeting their social needs, while still being able to be pulled by someone else in their tribe, because personal independence and mobility was not that high a priority for them, but being involved in the community was very high. An urban wheelchair was unfit for their lifestyle, culture or physical environment. Dr Walker said that so much of urban technology is aimed at the top end of our market, rather than basic needs like water, food and technology like washing machines and showers for people to stay healthy.
Dr Walker himself is a maker, and although he is following an unusual career path by focusing on appropriate technology in remote communities, he is nevertheless an insider of the dominant party, white, middle class and well educated, like most makers and hackers (Lindtner; Christina Dunbar-Hester). Dr Walker is a Western scientist with a great deal of agency and resources at his disposal, compared to the remote communities he is working with (Christina Dunbar-Hester).
His designs are definitely hacks, “a material practice that produces difference”, although his inventions are not of “the computer, network or communication technology kind” (Jordan). His washing machine, chip heater and mobility aids are basic engineering, and yet shows a mastery of technology to create it, they are impressive to other scientists in their simplicity and practicality and he finds his work “challenging and rewarding” (Jordan). Dr Walker, like Kamal the graphic designer interviewed by Irani, understands the importance of language and how it can frame and limit the conversation around innovation. In Kamal’s case, he had to re-educate people on their idea of what could be labelled “Indian design”. In Dr Walkers, he must make sure people do not give urban names to solutions like “wheelchairs” rather than “mobility” devices, because that limits engineers and designers thinking about solutions that would be “appropriate” for remote communities. He stresses that the value of technology is weighed based on our own culture and lifestyle preferences, not that of remote Aboriginal communities, and his designs need to try to ignore those assumptions and make things more appropriate for the people’s culture and lifestyle he is trying to help.
The video does not show how the Pintupi people might have appropriated technology directly, but it alludes to it. It talks about people “misuse” technology, and Dr Walker talks about people trying to teach the community how to use technology “properly”, so I am assuming they often use it in a way that suits them, rather than in the manner it was designed to work. Given their low power relative to the white urban designers and global manufacturers, Eglash would call their reinterpretation, adaption or reinvention an appropriation of technology (Eglash), by changing the nature of their relationship with the technology away from consumer towards producer.
Just like the people at DevDesign studied by Irani, and those not-for-profit and development bodies they work with, Dr Walker is trying to help the people of the Pintupi tribe and others in remote Australia. Both the Pintupi people and the villagers of India are in a period of drastic, rapid change, transitioning from traditional lifestyles to a more modern one, and the rest of the world is worried they will be left behind. Dr Walker is trying to train remote communities to repair their own technology, but also to innovate in the way they provide for their own basic needs, like food and shelter and cleanliness.
But despite their good intentions, these organizations like DevDesign and the Center for Appropriate Design appear to be racialized organizations as defined by Ray (Ray). The use of the word “appropriate” is full of assumptions. Who determines what is appropriate for the remote communities? Nothing can be concluded from a 7-minute video from 1988, but listening with 2020 ears, it sounds like Dr Walker with his White credentials was the one making the decisions about what is appropriate for these people.
I base this on three observations, albeit from one video; the prima facie appropriateness of his inventions in the physical conditions, the implicit problem he is trying to solve, and the appearance of a lack of appreciation for the local expertise.
Firstly, Dr Walkers inventions are simplified versions of modern technology, but can we call them “appropriate” for living in the desert, if we leave all urban assumptions behind? I think two of the three inventions are quite inappropriate given the environment of the Outback and the nomadic traditions of these tribes. A washing machine that uses washing powder and water in the desert? A chip heater for hot showers in 120-degree heat? I do not presume to know what the priorities were for this community, and perhaps neither did Dr Walker, but in the cold hard light of 2020, these seem inappropriate. Had Dr Walker arrived from the city looking for ways to adapt and improve modern technology to the remote community environment, full of optimism that technology had the power to transform their lives? It appears that way.
Secondly, I wonder what problem he was trying to solve? If many technologies fail in these remote conditions, it is perhaps not enough to merely change the materials and the mechanics to last in this environment, but one must look at the wider purpose of the technology and see if its solving the most pressing problem for the community. Dr Walker’s Center might be tinkering with narrowly defined problems as is often done in crowd sourcing competitions as described by Majchrzak and Malhotra, when he could be tackling major wicked problems that may not even have a technological solution (Majchrzak and Malhotra). I think despite his wish to do away with assumptions, he walked into Kintore with assumptions about the top priority problems of the community were, and that no matter the problem, a technology solution was the answer.
Dr Walker believes he has solved the problem of the better washing machine or the better water heater. He compares his inventions to the suitability of high technology, but what other comparisons should be made? Were there non-technical solutions to their problems? Was it even a problem to them? I cannot tell from this video as no Pintupi voice is heard.
This “problem” could be an issue the urban culture has with traditional culture, and these efforts are part of the hegemonic communication campaign to bring urban (dominant) values to the remote communities. Washing powder would cost as much as four times as much as in urban stores and is not readily available. Are the likes of Proctor and Gamble and Unilever (makers of OMO, see Figure 1) interests served by inventing products and trying to link washing machines to health and cleanliness to keep this community using their washing powder?
Figure 1 Screen Shot from the Emberson video
Perhaps if Dr Walker looked even deeper again at why someone used technology incorrectly, he might actually see what traditional solutions people used well before the advent of technology, and try to design with the community to come up with something that really suits them, even if its not “scalable” or “glamorous”. The solution may have very little technology involved at all.
The last clue along the lines of the Center possibly being a racialized organization is the omission of any form of “innovation” made by the local people. It illustrates Irani’s research on how there is a cultural and hegemonic process to determine what can be called “innovative”. In line with Irani’s theories, in order to be innovative, the invention must be scalable beyond the local needs of a remote community, yet it must also align with white peoples’ view of what Aboriginal innovation should look like. Perhaps the “chip heater” and the “mobility device” designed by Dr Walker were originally designed by the locals, and Dr Walker copied their creativity? Maybe their designs were jugaad and therefore not sophisticated enough to be called innovation, so he had to “modify” them to turn them into legitimate “innovation”?
This video was only 7 minutes long and I am watching it with 32 years of hindsight, but there are still clear signs of the urban culture defining what is “appropriate”, what is the problem and who is the innovator. I think if this video were produced today, the journalists would take more time to give credit to the local people, and their traditional way of life and skills. They would include the community in the process by running workshops and training them to see their own “problems” and “opportunities” just as DevDesign did with the Indian village people.
Ray, Victor. “A Theory of Racialized Organizations.” American Sociological Review, vol. 84, no. 1, SAGE Publications, 2019, pp. 26–53, doi:10.1177/0003122418822335.
A thought provoking task given to me in class this week was about comparing the practices of hacking and appropriating technology.
Tim Jordan’s Introduction talks about hacking, the hack and hackers and outlines his research in order to justify his definition of the hack. His definition is “a hack is a material practice that produces differences in computer, network and communication technologies.”(Jordan).
Jordan starts out by discussing hackers’ points of view to illustrate what a hack is and how even within the hacker community there are differences in the meaning and objectives. He contrasts creative, “make something new out of something old” hackers like Torvalds who created Linux, the first open source software, with hackers in the “black hat” sense, such as Erik Petersen, who wants to create something but also gain access, or hidden knowledge and basically do something that isn’t allowed. Indeed, some hack for political or activist purposes, called hacktivists.
Wark’s work is discussed by Jordan, in his view hackers are the new revolutionary class: subversive and anti-establishment, and Dunbar-Hester illustrates that with the example of the Free Software movement to break the corporate tyranny of companies like Microsoft with their software licensing regimes in the 80s and 90s (Christina Dunbar-Hester).
As a result, as Dunbar-Hester points out, many hackers believe that hackers using their skills as described by Rayner for hackathons, open source software and start-ups are corporate sell-outs.
So it’s not a requirement for every hacker for the “material practice” to be illicit for to be a hack. The hackers all seem to agree that the hack must be creative and new, and impress others in the hacker community.
So how does hacking compare with Appropriating Technology as outlined by Eglash (Eglash)? Appropriation changes technology and uses it in a way that was not anticipated by the manufacturers (Eglash). In this way, it is like hacking, because something new is created that is different to how it was intended to be used. There is also that subversive element, where the appropriators were not considered in the design of the technology but have been able to bend it to their will. This is also similar to hackers.
Appropriators are not limited in their technology to computers, networks and communication technology as hackers are however, such as the example of low rider cars. In addition, as Dunbar-Hester explains, hackers tend to be white Global North males, so in terms of the power axis, they are at the top of the scale. Appropriators have low power in society but find a way to make technology work for them even though the designers did not include them in their process. Hackers are however the ones designers have in mind when designing technology.
Although individually a hacker may feel they are a minority and outcast from society, and that is often what drives them to become a hacker, you can see from the results of their hacking that they are well connected. Hackers (software engineers) are now running the world! So, power shifted from white male service and physical workers to white male knowledge workers , but still within the ruling class. Hackers have a lot of agency, they can afford the technology and are very well educated and connected to it, just like with makerspaces, so this makes them very different to Technology Appropriators.
References
Christina Dunbar-Hester. Hacking Diversity. Princeton University Press, 2019.
Eglash, Ron. Appropriating Technology: Vernacular Science and Social Power. U of Minnesota Press, 2004.
Jordan, Tim. Hacking: Digital Media and Technological Determinism. Polity, 2008.
In today’s society, pursuing innovation is a cure for many ills, and sometimes a end in itself. In the concluding week of my innovation course, we looked at a couple of themes of dissent against the cult of innovation: that innovation is a hegemonic practice (Lilly Irani) and that innovation is has many downsides and there are other options (Russell and Vinsel).
Firstly, Lily Irani talks about how innovation is not really about creativity and invention, but rather about society recognising or even granting value to an invention, deeming it as innovation because it conforms to society’s ideals of what innovation is and who innovators are and what innovation is desirable (Irani). It has nothing to do with real creativity, novelty and invention.
Secondly, Russell and Vinsel talk about how the focus on new inventions, new infrastructure and new products is a cult of innovation, and this reverence or adoration of innovation renders invisible the work that needs to happen to keep all these innovations running, and the world as we know it functional (Russell and Vinsel).
In the first module of my course, we read Godin who explained how notions of innovation as good or bad have changed over time (Godin). Johnson was one wrapped up in a cult of innovation, where innovation is pursued as an end in itself rather than a means to an end. As Godin and Berkun explain, today innovation is always perceived as good, even though there are winners and losers with every new innovation. Russell and Vinsel talk about this same cult of innovation, and how by focusing on maintenance, society could make ethical decisions about which innovations we should keep, once we know their consequences. We should assess their benefits and costs and assign resources appropriately.
Russell and Vinsel explain how techno-optimism and the obsession with building new things (“innovating”) means that maintenance costs are seriously under-estimated and are under-funded. The work of the maintainer goes unrecognised, undervalued or not valued at all. Maintainers are often women and people of color, people in uniforms who are instantly recognisable (like a caste) and also as Dunbar-Hester explained, those with masculine skills. Ironically, these days in the “knowledge economy”, manual labor and service skills are also undervalued because they use traditional knowledge, physical skills, and are not making something new. This is similar to Haring’s discussion of ham radio technological culture and how electronics has been deemed to be a masculine pursuit, but it is interesting to note the fine point that these would be the white, middle class tinkerers and geeks rather than plumbers and builders and service people.
Irani refers to Russell and Vinsel in her book, and how innovation is overvalued, and maintenance is undervalued and invisible. She also points out that instead of technology investment as the only form of innovation, there are many other ways to ways to invest, such as film, textile design, music as innovations. But the main point of her book is that drawing the line between proper innovation and mimicry, inauthentic or even copies is a social and political act, just as we read about in Shenzen with shanzai.
Irani shows how Indian craftspeople, like the makers in Shenzen, are told to be creative but within the boundaries of what the dominant parties see as their role and their preconceived notions of their Indianness and Identity. To me, this is very much used as a hegemonic practice by the dominant party, using communication to ensure that the subordinates change in an orderly fashion and do not revolt. As Irani asks, “what powers are served by the call to innovate?”. The powers of the capitalist economy, the free market and consumerism, and the Global North?
WORKS CITED
Berkun, Scott. The Myths of Innovation. First edition., O’Reilly, 2007.
Christina Dunbar-Hester. Hacking Diversity. Princeton University Press, 2019.
Godin, Benoît. “Innovation: A Conceptual History of an Anonymous Concept.” Edward Elgar Publishing, vol. 25, no. 32, 2017, p. 36.
Haring, Kristen. Ham Radio’s Technical Culture. The MIT Press, 2006. DOI.org (Crossref), doi:10.7551/mitpress/3405.001.0001.
Irani, Lilly. Chasing Innovation Making Entrepreneurial Citizens in Modern India. eScholarship, 2019.
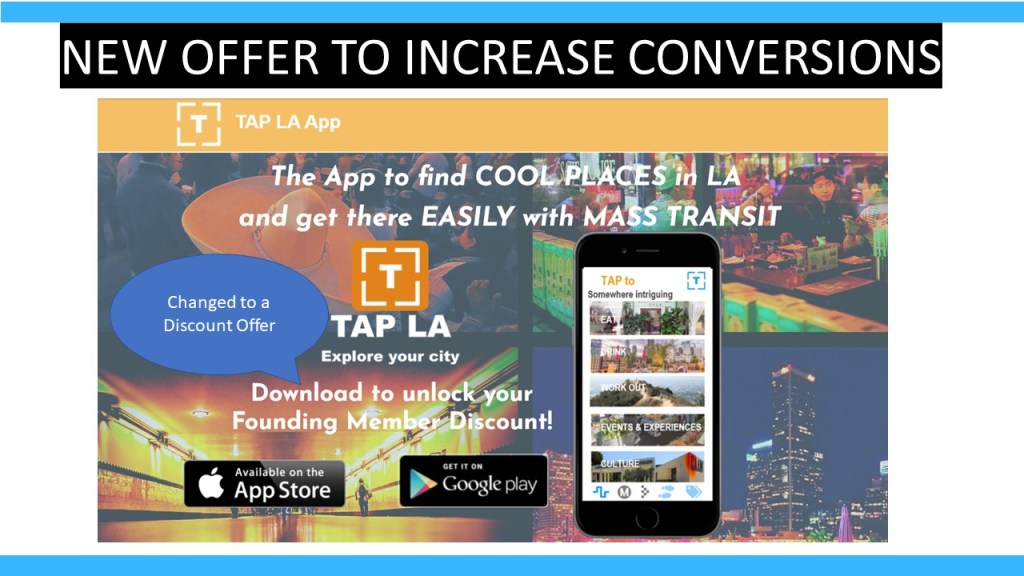
This Spring, in my final semester in my Master of Science (in Communication Data Science) at University of Southern California, I had the pleasure of having Jaime Levy as my Professor for UX Strategy and Design. She is one of the trail blazers of digital media and has written a great book called “UX Strategy: How to design innovative digital products people want.” Her classes are informative, challenging, and an absolute riot. We all worked incredibly hard, producing a new element of our product and presenting it week after week, and I had the most fun of my entire Masters program.
The product idea I worked on is called TAPLA, which I imagined to be the new Go Metro App. You could re-load your card and get route maps etc, but most importantly, you can find cool stuff to do on the Metro train and bus routes! And you get rewarded for using it!
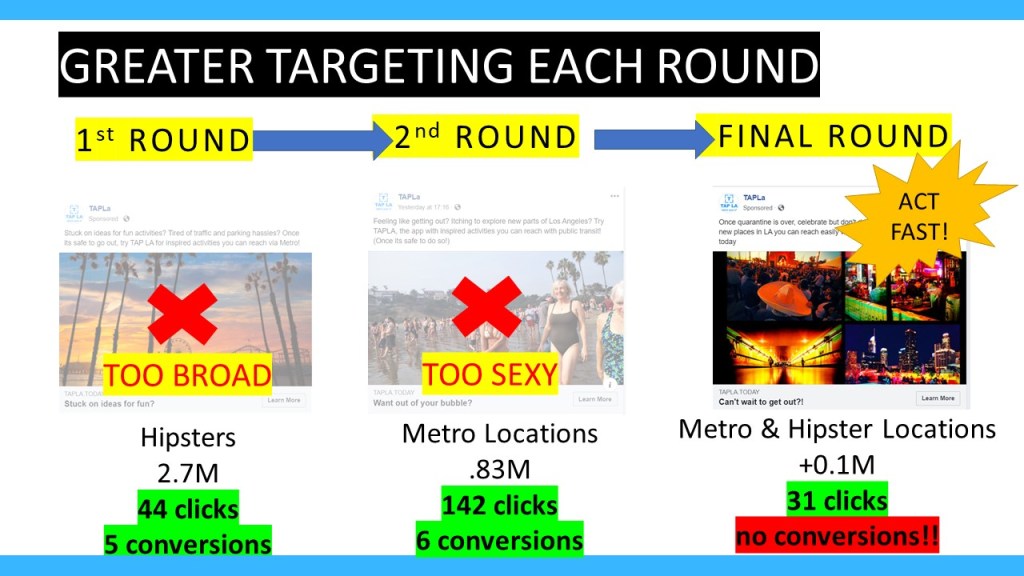
Throughout the semester, I “got out the the building” and decided to “move fast and break stuff” ! I conducted customer research at Culver City, finding 10 kind volunteers to interview. I reviewed the marketplace, looking at Go Metro app, and competitors who provide navigation, experience discovery and those like Yelp and Discover LA who provide both. I made an interactive prototype in Adobe XD and recruited 5 people to give me live feedback on it in an interview (Jaime calls this guerilla research). I built a landing page to drive app downloads and then ran 4 Facebook campaigns.
I had mixed success in terms of conversions but I learned a lot!
1st lesson: really know your value proposition and be able to articulate it leftside, rightside, forwards, backwards, upside down and underwater.
2nd lesson: make sure all copy and images express the value prop or you will waste time and money sending people to your site who are just not interested in your product i.e. dont use a bikini clad woman if you aren’t selling bikinis.
3rd lesson: talking to potential customers is the best part of the job! Don’t be afraid, people are so lovely (I was paying them but I think they are just lovely anyway).
Final lesson: Adobe XD is really flexible and gives you interactive prototypes you can video and share easily, it’s really worth learning.
Over the last few weeks in class we have discussed the regional innovation phenomena, studying recent examples such as Silicon Valley (Northern California, USA), Silicon Alley (New York, USA), Shenzen (in China) and practices in India. In this paper I review a recent project with objectives of stimulating regional innovation, on the shores of the Toronto lakefront, and consider how partners Sidewalk Labs and Waterfront Toronto are handling the project. Specifically, I address what mistakes they might be making and make recommendations for more sustainable long-term regional development.
Waterfront Toronto is according to their website:
“…the public advocates and stewards of Toronto’s waterfront revitalization. Created by the Governments of Canada and Ontario and the City of Toronto, our mandate is to transform our city’s waterfront by creating extraordinary new places to live, work, learn and play.” (Waterfront Home)
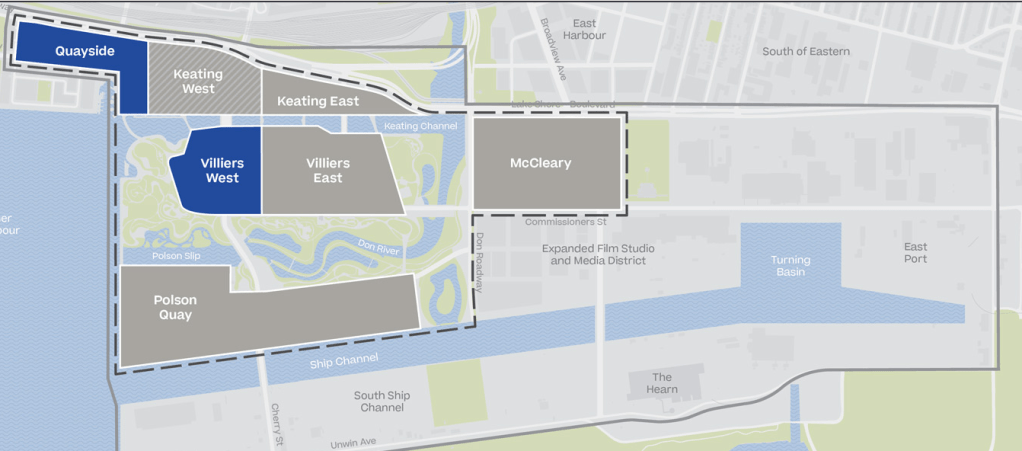
One key element of their 5-year strategic plan was to work with a private company as their innovation and funding partner. Sidewalk Labs, a subsidiary of Alphabet and sister company to Google, was awarded this contract in October 2017. Sidewalk Labs submitted a $50M bid to develop a Master Innovation and Innovation Plan jointly with Waterfront Toronto. Their bid included an impressive 200-page detailed outline of a smart city “built from the internet up”, beginning with Quayside (12 acres), and then expanding across the River District to become the Innovative Design and Economic Acceleration (IDEA) District (190 acres) as shown in Fig.1.
Fig. 1 Sidewalk Labs IDEA District (Sidewalk Labs, “IDEA District”)
The website for the project Sidewalk Toronto is Sidewalk Labs tool for public engagement. The site outlines 5 objectives: job creation, affordable housing, mobility, sustainable and climate positive development, and urban innovation.
We were assigned two critical articles to read, one by Sauter written for the Atlantic in early 2018 shortly after the project was launched, and another by Bliss written towards the end of 2018 for CityLab.com (Sauter; Bliss). These articles raised serious questions about who gets to decide what a city is used for, how companies should use your data and how much power should be given to private companies by government when developing cities. Bianca Wylie, a “civic tech reformer” whose interview was the subject of Bliss’ article, held grave concerns that government would allow Sidewalk Labs to direct the development of the entire 800-acre Waterfront site. Both Bliss and Sauter’s articles, although early in the planning process for Quayside, highlighted the concerns of the public and activist groups at the time. These concerns included a lack of genuine consultation with the public, lack of due process and transparency when Waterfront Toronto had awarded Sidewalk Labs the contract, lack of consideration for data privacy of the potential residents and that the entire process was un-democratic. Waterfront Toronto did not even release the contract to be reviewed by the City of Toronto Council until public pressure forced them. The pressure must have been intense, because by Fall 2018, the CEO of Waterfront Toronto had resigned, three board members of Waterfront Toronto were fired including the acting CEO and Chairperson following an audit by Ontario Province, and Bliss reports that three project advisors quit due to concerns about data privacy and apathy and lack of leadership regarding shaky public trust (Bliss; McLeod).
Indeed, since these articles were written, Sidewalk Toronto has made efforts to address the public’s concerns. The planning process was originally meant to be a co-creation of the plan (Sauter), however it appears as though public pressure resulted in Waterfront Toronto distancing themselves from sidewalk Labs to be more arms-length: Sidewalk Labs would work on the plan and Waterfront Toronto would work on the framework to assess it.
By late November 2018, the draft site plan was released and Waterfront Toronto’s objectives have changed: they have dropped Urban Innovation and replaced it with Data Privacy and Digital Governance reflecting the public’s concerns (Sidewalk Labs, Quayside Draft Site Plan). However, Sidewalk Toronto’s website accessed in March 2020 still headlines Urban Innovation as a key objective and made no mention of the other two.
In June 2019, Sidewalk Labs draft Master Innovation and Development Plan (MIDP) was released by Waterfront Toronto, along with an open letter from Waterfront Toronto’s CEO. Both documents were made available online, and the open letter immediately advises the public of the issues it has with Sidewalk’s plan: that it is premature to expand from Quayside to the entire IDEA District, that presuming the lead developer contract would be given to Sidewalk is wrong, as there needs to be a tender process, that the conditions for the success of the plan require investments that are beyond the ability of Waterfront Toronto to make and that they need to ascertain compliance of the data collection proposal. The open letter closes in a way that echoes the concerns raised in our two readings and tries to convince the public that this project is still in negotiation (Diamond).
“Whether the Quayside project proceeds or not, the conversation we are having is important for all of Toronto” Stephen Diamond, Chairman and CEO of Waterfront Toronto (Diamond).
In July 2019 the parties signed an amendment to the Plan Development Agreement which this time was made available online for the Toronto Council and general public to see (Waterfront Toronto and Sidewalk Labs).
Then in October 2019, after some public consultation, another open letter was released explaining that agreement has been reached with Sidewalk Labs on all of the issues, and Waterfront Toronto would then begin to formally review the revised MIDP. The issues were resolved as such: scope revised back to Quayside site only, the plan makes no demands of other government investment, it includes a data management plan and clarifies Sidewalk Labs role as a partner to lead developers, who will be determined through competitive tender. It also reaffirms Sidewalk Labs commitment to an urban innovation fund whilst making a commitment that 50% of investors will be Canadian. Still, the CEO remarks of Quayside, “this is not a done deal”.
Despite all these efforts to assure the public that Waterfront Toronto and Sidewalk Labs are listening to the people of Toronto and have their best interests in mind, in January 2020, Waterfront Toronto announced that they have pushed back the decision to move forward on the Quayside project from March to May 2020 to give more time for public feedback (Waterfront Home). This means the project is at least 7 months late, as planning was only meant to take 12 months. At this stage, it isn’t overreaching to say that Sidewalk Labs and Waterfront Toronto appear to have lost the public’s trust, and the entire “smart city” project could be in jeopardy. So where did they go wrong?
In a nutshell, my take on this is that Sidewalk Labs fundamental mistake was presuming that the people of Toronto are techno-optimists as they themselves are. We have learned that techno-optimists believe that if governments would just get out of technology companies’ way, they would solve all the worlds problems. Lindtner describes how techno-optimists from Silicon Valley and the West are attempting to bring this ideology to China, and Lilly Irani talks about the same phenomena in India. Influencers like MIT and Silicon Valley companies set up shop there looking for governments, corporations and investors who are also believers to help them colonize these countries with their ideas and be able to profit from these more undeveloped economies and legal and regulatory frameworks. However, Toronto is a far different technological place, that has similar social and legal systems to the US, and in addition a healthy skepticism of big US companies and their promises of economic development. According to the readings, Canadians have had a long history of such US companies either poaching successful startups to move to the bigger market of the States, or setting up in Canada only to pull out when economic times got rough (Sauter).
IMO, Sidewalk Labs first misstep was revealing too much in their 200-page submission in order to win the bid. Their intentions and their assumptions were immediately made clear, and the savvy people of Toronto were very uncomfortable at the size of their ambitions. They perceived that Sidewalk Labs needed the scale of the entire Waterfront site to bring their vision to life, not to mention unfettered access to all residents’ data. Lindtner and Gu and Shea explained how the Chinese government might allow companies to do this in China, in order to make efficient and innovative cities with free maker and hacker spaces and new products and services for the Chinese people, but this was not going to be an acceptable trade off for Canadians.
Possibly blinded by techno-optimism, and perhaps assuming that of course a smart city is what every Torontonian wants, it’s the natural solution for economic growth? Waterfront Toronto seem to have jumped straight to this conclusion too, that of course a smart, data driven city is the best idea and they should partner with a technology company like Sidewalk Labs. This assumption was quickly proved wrong, because like Americans, Canadians value their privacy and believe in democracy, and need to be included in the decision-making. Lindtner explained Orientalism, where the West treats the people of China as “others” that they can distance themselves from and take advantage of without guilt on the basis of these perceived differences. But Canada are by no means “others”, Canada’s culture and values are so similar to the US, so there is no excuse of “cultural differences”. I am astounded that Sidewalk Labs and Waterfront Toronto could have made such a fundamental error to assume people would be willing to give so much up for the sake of technology. There are of course many other options for development, such as expanding other industries like the independent film industry in Toronto, and improvements, repairs and maintenance of existing services and infrastructure, so the people of this city want to be part of any process that decides what their city is for, who they partner with and who benefits from living and working and investing there.
The other concern raised by Bianca Wylie and other community members was that Sidewalk Labs and Waterfront Toronto were not government bodies and should not have the power to facilitate or make these decisions (Bliss). Sidewalk Labs are a tech company, not city planners, or elected representatives, and people complained their “consultation” was more publicity and marketing. Their lack of engagement hints that they did not have the desire or perhaps experience to navigate this kind of wicked community problem?
According to critics, not only did they lack the credentials, mandate or experience themselves, they were keeping the City of Toronto and its constituents in the dark about the terms of the initial agreement and the process to award the contract. This really damaged the relationship with the government, and damaged the reputation of the City in the eyes of their constituents that they were to deliver a good outcome for Toronto. This kind of behavior also resulted in removal of some board members of Waterfront Toronto. Western companies in China and India take a very different approach with those countries’ governments, helping them and other influential parties solve their problems. Taking a hostile approach was a big mistake in my opinion.
Unlike the entrepreneurial citizenship discussed by Irani that was welcomed and encouraged in India by the government, Canadians were aghast that such nation-building powers were being ceded to a US corporation, and that the process was undemocratic and opaque.
Sidewalk Labs wanted to make the IDEA District a huge, government subsidized low cost makerspace like those described by Wen, Gu and Shea and Lindtner in Shenzen. However, they wanted to bring all their Silicon Valley investors and transient employees in to use these great facilities. They did not make plans for a community to take root. Bliss and Sauter explain that the commercial space was all modular and configurable and suitable for pop ups. The residential spaces and the services to support them weren’t suitable for families, or workers who might need to commute from other parts of Toronto to provide services, but more focused on single professionals who would live two steps from their office and never need to use a car. The physical configuration reflected their notion of what a tech community looks like. This MDIP would not resolve Toronto’s accommodation shortage or high cost of living. Irani, Lindtner and others explained that makerspaces were often only accessed the upper middle class, and the luxury of being an innovator was only afforded to the well-educated and those with agency to be a maker. This seems part of the Sidewalk Toronto plans also, and that lack of understanding the demographics of Toronto seems another mistake.
Sidewalk Labs perhaps thought they could transplant their network from Silicon Valley and New York into Toronto, and apply their influence on the governments of Canada, Ontario and Toronto. Sidewalk Labs revealed in their initial proposal, their draft site plan and their draft MIDP they wanted Waterfront Toronto to give them significantly more scope than they originally planned, clear legislative “roadblocks”, develop special economic zones with low taxes and low interference for Sidewalk Labs, and divert public infrastructure investment to support the development of the smart city. In Shenzen and India, the US companies understood the importance of giving a local look and feel to their projects in order to convince locals that the project was in their best interest (even if it wasn’t). But critics believe Sidewalk Labs failed to do this. If anything, this came across as a hostile takeover of the Toronto Waterfront project. As O’Mara states, Silicon Valley is a symbol of the American Dream, but the response from Toronto appears that this Silicon Valley dream is not a Canadian one.
Irani talks about the importance of empathy as a form of hegemonic communication when the dominant party wants to convince the subordinate one that what is good for them is good for all. However, Waterfront Toronto and Sidewalk Labs did a terrible job of displaying any empathy. Wiley describes the project’s communications as not even PR, but essentially crisis communications, where they were trying to see how little they could reveal, how much they could get away with, and only provide information when they were pressured by activists like her. If so, this is atrocious communications and community consultation, and it is no wonder the public lost trust and faith in the project.
I have a number of recommendations for future smart city projects to address these mistakes and make the project more long-term and sustainable.
As explained above, Waterfront Toronto made changes after the two articles we read from 2018 were written. They became more transparent, they included the City in their processes, they gave more than enough time for community consultation and they separated themselves from Sidewalk Labs. These changes make a lot of sense, but they came far too late, the trust was already evaporated. For future projects, I recommend that they are completely transparent with their agreements, and ensure their governance is best practice, and they should hire locals for highly visible decision- making roles.
The underlying recommendation is about building trust, empathy and knowledge about the community and government you are working with.
It is vital for urban developers to gain the trust of the government in the first instance, and then secondly the citizens. To do that, you need to understand the culture that you are working in. I recommend in future companies work with the community and government to first define who are the stakeholders, then define the problem, and the city’s objectives, and only then see how they could help solve these problems.
There are winners and losers in every big change like this, so it is important that the government consult with the community to fully understand all the possible impacts, and try to find a way to minimize and alleviate some of the externalities this project might create.
The development council should conduct vigorous community consultation process before they begin any project planning. If the local council has not done this already, include cost and time for this process in your development proposal. This needs to be true empathy, not an exercise in justifying pre-determined outcomes, unlike the examples given by Irani in India.
I recommend that developers explain to the community how the benefit will be shared with the community members as well as the government and the corporations. They also need to protect the fundamental individual rights of the community, in accordance with the community’s values, such as data protection and individual privacy, and family values in this case. I can really see the importance of ethnographic and critical studies to understand the culture and the community, because developers would be a lot more successful if they understood this.
Of course, this information may not actually change the level of community exploitation the developers pursue. It may actually have the sinister effect of helping the developers improve their hegemonic communication and other practices in order to gain community acceptance of the changes they are proposing, and therefore that would make any change more long-term and sustainable in that way. If successful, their communications could make the majority feel like winners, and disenfranchise and dehumanize the losers, so that most people feel happy that the project is in their best interests, even if that is all smoke and mirrors.
To echo Sauter’s closing remarks, deciding who a city is for and who decides how they grow is indeed a wickedly complex problem. For innovation and development to be sustainable and long-term, the decision makers need to truly understand the community and the culture they are working with in order to be able to communicate the project and sell it to the people.
Whether the innovation is truly in a community’s best interest, only time and the history writers will tell.
Lilly Irani conducted a multiple year critical study of design schools and entrepreneurship in India, participating as a designer and an ethnographer with one particular design studio for a number of years. Irani is both a researcher and an tech professional. In her book, Chasing Innovation, she coins the term “entrepreneurial citizen” to explain how civil movements and centralised government planners have handed over the responsibility of social change and nation building to the entrepreneur. Entrepreneurs, and the designers Irani studied, who once had managerial roles responsible for building businesses for investors, are now encouraged to take their passion for social justice and development and channel it into scalable design projects with global market possibilities for growth and profit. Irani points out that proponents of very different models of development still all believe that entrepreneurship and private innovation is the answer to India’s problems.
According to Irani’s research, this change has been brought about through communication in order to supports the capitalist ideology of the elites, political and industrial interests. Rather than rising up against these dominant groups, people are persuaded through communication to believe that anyone can be an entrepreneur no matter what their background, and that they can create enterprising ventures, save the world and make money all at the same time. In this way, Irani’s concept of entrepreneurial citizenship is a very subtle tool of hegemony. Instead of political dissent, issues are framed as “opportunities” for “value creation”. If the target users (usually the poor of India) are not interested in the proposed solution because its not their number one problem, these concerns are labelled “perceptions” and blithely ignored because they do not align with the investors priorities.
Irani explains that entrepreneurial citizenship empowers the middle class, who are well educated, outspoken, can speak English and convince investors that they add some intangible but essential value. This value add tends to be a theatre of empathy with their potential product adopters, because as noted above, it’s the investors priorities that come first, not the users.
It does not empower the users unless the dominant class also benefit from their adoption of the entrepreneurial development. Irani speaks of how in fact capitalism can leave so many people dispossessed and in poverty, as it moves value up the chain and away from the people who labour.
At the end of the day, investors want a product with global scale, so something that is adopted by millions of India people is very attractive. This idea of entrepreneurial citizenship empowers global investors to get access to Indian designers and the poor of India as potential consumers, so they too benefit.
Governments are still in control of vast public resources and networks, and they ultimately determine what designs are funded, and now instead of having to explain their decisions to convince the public, they can now just fund innovations and be seen to be supporting development of all peoples. So this concept of the entrepreneurial citizen empowers them too, or at least maintains their position of power.
Hence the idea of the entrepreneurial citizen gives the middle class enough of a carrot to stop them from being effective political opponents to those already in power, and maintains the power of the elites, governments and industry, and keeps the poor in poverty.
In fact, Irani explains that design is essentially hegemony too, because if product design is done well, it is invisible and steers the users to outcomes deemed desirable by the investors without them being aware of it. So the entrepreneurial citizen and their practice of human centred design does not seem likely to be the silver bullet for India’s growing population and poverty.
Reading Wen Wen, and Gu and Shea and a preview of work by Lindtner about Shenzen, I was asked to reflect on what is Chinese maker culture and who or what forces are cultivating it and why.
These works put forward a picture of Chinese maker culture as a hard-working ethos, that has arisen from traditional manufacturing, moved to shanzai (imitation phone manufacturing in small batches) to what Wen calls 0-1 makers and makers to makers which are individual makers and makers working together in makerspaces. Lindtner describes shanzai as an idealized form of grassroots experimentation that operated across a range of scales, from local to vast, and how it is perceived as “hacking with Chinese characteristics”, or the orientalised version of making. It is apparent that Chinese maker culture and identity came about through social engineering from government, business people and foreign interests cultivating it as opposed to being a grass roots movement. Wen ironically calls it “top-down grass-roots innovation”. As a result there are different points of view on what Chinese maker identity means depends on which cultivating force you are considering.
According to Lindtner, Eric Pan founder of the Shenzen based open source hardware company Seed Studios is a champion of shanzai 2.0, which combines the manufacturing efficiency of shanzai with open-source and open innovation. Pan struck a nerve when he situated shanzai in a long tradition of Chinese ingenuity, aligning shanzai to the Philopsher and inventor Mozi. Lindtner argues that Western maker culture is all about fun, social impact, self-realisation, invention, hobbies and tinkering, rather than manufacturing efficiency and hacking out of necessity. Pan’s positioning of shanzai 2.0 has legitimised shanzai in the eyes of the makers of the West, because it is aligned with Western values but still providing enough difference and oriental flavour to keep Chinese makers as “other”.
This leads on to why Lindtner argues that Western influencers such as MIT Media Lab (Fab Labs) and Makers and corporations need to see Chinese maker culture as “other”. He describes their disillusionment with the Western techno-utopia, and their fears that the West is a “broken world”, so they look to China as a source of renewed optimism, because of their perception that China is a “temporal other”, stuck in the past and still replete with opportunities for technology to do good. Xin and Shea argue that the West use Chinese maker culture as a “soft-landing” for their brands and ideas, to introduce their product to Chinese markets and also access the Chinese manufacturing supply chain.
Lindtner talks about the free culture movement and Lessig’s belief that shanzai creative copying is actually piracy. Essentially unless copying is done in a fun, carefree and profit-free way, it is bad, therefore someone only has a right to hack if they still respect the underlying ideas of IP, ownership and authorship.
But David Li and Huang argues that shanzai represents China’s right to hack, and that IP laws are unethical and it is shanzai that is morally and ethically correct. Chinese makers are like Robin Hood, righting the wrongs of an unfair IP regime imposed by the West.
The Chinese government support makers through tax breaks, infrastructure, education, R&D support and other means, because encouraging frugal innovation is low risk to them as makers are “venture labor” described by Gina Neff last week. Their agenda is to have mass innovation that will continue to refresh the Chinese economy, so that’s how they support Chinese maker culture.
Therefore there are many different rationales and perspectives on Chinese maker culture but they are all working towards giving it legitimacy and relevance.
Image from Silicon Valley opening credits , HBO series (I dont own the rights)
Excerpts from books by Indergaard and Neff describe Silicon Alley: a new media hub located in downtown New York City from the early 1990s with ambitions to become a regional innovation hub like Silicon Valley in California. Silicon Alley grew rapidly during the dot.com boom but failed to withstand the dot.com crash at the end of the nineties. A number of start ups focused on the NY media and advertising industries were successful such as Razorfish and DoubleClick, but the majority of start-ups could not convert their creativity into commercial corporate value, and many of their clients used them as contract labor and eventually built their own in-house capability.
So why was Silicon Alley unable to thrive as Silicon Valley did? From this weeks readings I can find three possible causes: homophilous networks, lack of resiliency to economic downturn, and hype rather than real industry.
The kids of Silicon Valley were young, hip and edgy. Their version of networking was clubbing and partying, they even called their community “The Scene”. Their networks were dense and homophilious, because being able to network till late created strong friendships but at the same time created exclusive cliques, as it was not something people who lived in the suburbs, or older people or those with family responsibilities could do. But regional innovation hubs need diverse, heterogenous networks to build bridging social capital, that can rapidly diffuse technological change, spark innovative ideas and foster partnerships and collaboration. This is very different to Silicon Valley, which was a tech hub with businesses from all industries, and employees from all over the world, which made it extremely diverse as explained by English-Lueck in our week 4 readings.
Not to mention that all that partying does not make you resilient. Schrock and Neff describe how the lines between work and personal time are blurred by the idea of Silicon Valley, which can cause people to burn out. People were also not geographically mobile, because who you knew was so important in Silicon Alley, so it wasn’t easy to import or export people from the Alley. In addition, Silicon Valley’s reliance on the media and advertising industry as clients of their creative output and lack of manufacturing base made it vulnerable to economic downturns. The creative Silicon Alley initially were able to “rise with the tide” of the dotcom boom, but the bust really hurt Silicon Alley, whereas Silicon Valley was more resilient.
Lastly, Silicon Alley was a victim of its own hype. As Dr Schrock states, Silicon Valley was a promise not a place. Silicon Valley situated in Santa Clara Valley California was absolutely the site of an incredibly productive and profitable regional innovation hub. In “Silicon Valley’s old money”, O’Mara also describes the long heritage of successful people mentoring the next generation of innovators, which really helps them learn directly from their mentors and in turn be very successful. But the export of Silicon Valley was a promise. When, as Indergaard describes, wealthy real estate investor Rubin began wiring vacant buildings in the financial district and offering them to new media start ups for low rents and short leases, he was banking on this promise. The area was branded Silicon Alley to strengthen the brand. Further hype was created by the establishment of associations and newsletters. But at its core, the creativity, edginess and non-confirmity of the Silicon Alley start ups was difficult to convert into business leverage. Established businesses doubted their business acumen from so much publicity around partying. Therefore, a strong business model was never realized and Silicon Alley never really recovered after the dot.com bust.
This research paper explores the psychological and social motivations for using the amazingly popular social media/live streaming platform Twitch by conducting a small survey of users.
Keywords: Live Streaming, Twitch, Social Identity Theory, Uses and Gratifications Theory, Psychological motivations
Psychological Motivations for Twitch users
This research paper explores the psychological and social motivations for using the amazingly popular social media/live streaming platform Twitch. This small survey of 87 participants could not establish a relationship between psychological motivations (information seeking, entertainment or social) and watching continuance intention. However, it did support the hypothesis and align with past research that those users who have online social identities aligned to the broadcaster do use the platform for information seeking and entertainment, and those who align their identities with groups of other audience members use Twitch for social motivations. A novel finding of this research was that whether or not people identified with Group or Broadcasters, they all experience para-social feelings towards the Broadcaster, and also a sense of community with other members, are driven by conformity motivations in their use of the platform, and share a co-experience of Twitch with other users in their group also.
Background
Twitch Live Streaming Platform
Twitch.tv is a live streaming platform where broadcasters stream content on their channel, mostly streams of themselves playing video games (Ewalt, 2013). Twitch is also home to official broadcasts of esports tournaments, and more recently hosting broadcasters of “real life” content (Wikipedia, 2019). Viewers can subscribe to broadcasters’ channels, to watch their live streams, and interact with other viewers and the broadcaster (when they read the messages) via stream chat. Some live streams have over 20,000 concurrent viewers, and the chat messages can stream past at what appears an unintelligible speed to a novice. Twitch audience have their own ways of playing around with chat in the extra-large live streams (greater than 10,000 concurrent viewers), such as using ASCII and copypasta art, in a style called crowdspeak (Ford, Gardner, Horgan, & Liu, 2017). Twitch chat is “simultaneously incoherent and enjoyable” page 5 (Ford et al., 2017). Through combining broadcast and the somewhat incoherent chat, Twitch is a new and unique form of participatory social media (Hu, Zhang, & Wang, 2017; Jenkins, 2006).
Since being spun off from its parent site, justin.tv, in 2011 (Ewalt, 2013; Ford et al., 2017), Twitch.tv’s popularity has continued to grow astronomically . According to Twitch’s own website, they have upwards of 1.3m concurrent viewers at any given moment, over 3m creators streaming monthly, and more than 15 m average daily visitors (Twitch, 2019). Half a trillion minutes were streaming in 2018 (Twitch, 2019), and in 2014 they were the 4th largest streaming site in the US (Ford et al., 2017; Hilvert-Bruce, Neill, Sjöblom, & Hamari, 2018). Clearly, Twitch is meeting a very prevalent need in society.
All of this is very bewildering to new users, or students of communication media who are unfamiliar with the platform. It prompts the question: why do people consume different types of media (Hilvert-Bruce et al., 2018). The purpose of this paper is to hypothesize why people use Twitch and test the hypotheses.
Literature Review and hypothesis development
The theoretical background for this research paper is grounded in two theories related to computer mediated communication: uses and gratification theory and social identity theory. The relationships between the theory, concepts and hypotheses are illustrated in Figure 1.
Figure 1 Conceptual Model for Research Paper
Social identity theory and social identification concept
In their study of intergroup conflict Tajfel and Turner proposed social identity theory, where people hold multiple social identities along with their individual one (Tajfel & Turner, 1979). These social identities form where we experience a sense of oneness and belonging to a community, and this can happen online (Hu et al., 2017; Xiao, Li, Cao, & Tang, 2012). Individuals seek to create online social identities (even when otherwise anonymous) and these identities help foster trust and information and social exchange between community members (Postmes, Spears, & Lea, 1998; WALTHER, 1996; Xiao et al., 2012). This social identification concept and forming of online social identities leads to continuous use intention(Chang & Zhu, 2011; Hu et al., 2017). For owners of online sites such as Twitch, continuous use intention is a key objective of the site.
Uses and Gratification Theory
Uses and Gratification Theory (UGT) attempts to answer the question about why people choose to consume different types of media (Hilvert-Bruce et al., 2018). According to UGT, media engagement behaviors are aimed at “the fulfilment of individual psychological needs” page 59 (Hilvert-Bruce et al., 2018).
Social motivators of media engagement behavior include information seeking, entertainment, and social motivations such as meeting new people, social interactions and support, sense of community, social anxiety and external support, however research has found social anxiety and external support were not supported as uses for Twitch (Hilvert-Bruce et al., 2018).
Information Seeking and Entertainment
A number of papers have information seeking and knowledge exchange/ sharing as a reason for use of social media platforms and online forums (Chiu, Hsu, & Wang, 2006; Ford et al., 2017; Hilvert-Bruce et al., 2018; Pendry & Salvatore, 2015; Xiao et al., 2012). Entertainment is also a psychological motivator in the use of social networking sites (Chang & Zhu, 2011).
Information seeking and entertainment are important motivators for using Twitch, because audiences can learn how to play games while enjoying watching the most experienced players in the world, either during tournaments or on their live stream channel (Ewalt, 2013; Hilvert-Bruce et al., 2018).
H1.1 Use of Twitch for information seeking and entertainment motivations are positively correlated with intention of continuation of engagement.
Social Motivations
Meeting new people, social interactions and sense of community are noted in research as important psychological reasons for using social networking sites (Chang & Zhu, 2011) and live streaming sites (Hilvert-Bruce et al., 2018). A sense of community online involves an individual experiencing feelings of belonging, having a say, fulfilment of needs, feeling a bond with others, and mutual influence between members (Hilvert-Bruce et al., 2018; Mcmillan & Chavis, 1986; Peterson, Speer, & Mcmillan, 2008). Online social ties form between members’ online social identities from the social interactions and sense of community they have, and further reinforce online social identity and social identification concept outlined in the previous section (Hilvert-Bruce et al., 2018; Xiao et al., 2012).
H1.2 Use of Twitch for social motivations are positively correlated with continuous watching intention.
Types and Antecedents of Social Identification
Further to social identity theory, social identification concept and UGT, research identifies two types of social identification for users of live streaming platforms: broadcaster identification and group identification (Choe, 2019; Hu et al., 2017).
Identification with the Broadcaster is motivated by individual identification in the classical sense: wanting to be like someone you admire (Hu et al., 2017). Broadcaster identification on live streaming platforms like Twitch is caused through the effects of para-social activity, where the audience has the illusion of an individual relationship with the broadcaster facilitated by the stream chat and the responses of the broadcaster to individuals requests (through techniques like footing and recruitment as explained by Choe, 2019 and Hu et al, 2017).
H3.1 Para-social experience is positively corelated to Broadcaster Identification through Twitch
This paper hypothesizes that along with para-social experience, audience follow certain broadcasts because they want to learn how they play video games (information) or because they enjoy their streams for entertainment reasons.
H2.1 Use of Twitch for information seeking and entertainment motivations is positively correlated with Broadcaster Identification.
Identification with a group is the sense of community (belongingness and oneness) generated through online social ties and social interactions that occur between online social identities (Hilvert-Bruce et al., 2018; Hu et al., 2017). Group identification occurs through the social interaction with other audience members facilitated through stream chat and also offline (Choe, 2019; Hu et al., 2017) and is caused by the social effects outlined above in UGT section. It can be measured in terms of co-experience, where interaction between members co-creates the community, through cognitive communion, resonant contagion and sense of community (Hilvert-Bruce et al., 2018; Hu et al., 2017).
Of course, communities form in real life (offline) too, and these groups can influence social interaction and sense of community occurring online and also be influenced by it (Jenkins, 2006). Social media enhanced real-time streaming video sites can reduce the physical distance between friends (Lim, Cha, Park, Lee, & Kim, 2012), they can encourage civic activity offline (Pendry & Salvatore, 2015) and generate a virtuous feedback cycle in participatory media (Jenkins, 2006). Chang and Zhu discuss that having a critical mass of friends on social media sites can encourage others to join them (Chang & Zhu, 2011), and therefore this conformity motivation could be another psychological motivation for use of new social networking/live streaming services like Twitch.
H2.2 Use of Twitch for social motivations is positively correlated with Group Identification.
H3.2 Conformity Motivation, Sense of Community and Co-experience is positively correlated to Group Identification
Method
Participants.
87 participants responded to the survey. The survey was administered over two 24-hour periods on the Amazon MTurk platform. The first batch yielded 52 responses and the second batch 37 responses. The second batch was performed in order to have a large enough sample for regression analysis (although this wasn’t successful). Survey participation was voluntary, and survey participants each received between USD$0.70 and $0.85 compensation via the MTurk platform.
80% of the survey participants identified as male and the remaining 20% as female. 72% of participants were between 25-34 years old, 14% were 35-44, 9% 18-24 and 5% were 45-54 years old. The participants were in either the USA or India as shown in Figure 2 below. The size of the circle indicates the quantity of responses from that location.
Figure 2 Location of participants
Present Survey
The survey consists of 38 questions obtained from past studies outlined in the Literature Review section, whose responses were examined for pairwise positive correlation to prove the hypotheses. See Table 1 for a summary of the areas of the survey and the number of questions.
Scale
All responses are measured using a 7-point Likert Scale: Strongly Disagree, Disagree, Somewhat Disagree, Neither agree nor disagree, Somewhat Agree, Agree, Strongly Agree.
Engagement measures
This paper measures engagement with Twitch using continuous watching intention (Chang & Zhu, 2011; Hu et al., 2017; Kang, Hong, & Lee, 2009). Although there are other measures such as self-reported frequency, psychological and financial, intention has been chosen as the right balance between easy to measure and yet less subjective (Hilvert-Bruce et al., 2018).
Information seeking and entertainment motivation measures
Three questions explore information seeking motivations and two questions measure entertainment motivation (Chang & Zhu, 2011; Hilvert-Bruce et al., 2018) for Hypotheses H1.1 and H2.1.
Social motivation measures
Social motivations with reference to Hypotheses H1.2 and H2.2 are measured by multiple questions. One question to determine if Twitch is used for Meeting New People (Chang & Zhu, 2011; Hilvert-Bruce et al., 2018), six questions that explore the nature of participant’s online social identities, whether they know others’ or others know their screen name, real name or personality (Postmes, Spears, & Lea, 1998; WALTHER, 1996; Xiao, Li, Cao, & Tang, 2012), and one question to measure Online Social Ties by asking about frequency of communication with other audience members (Xiao et al., 2012).
Group Identification and Broadcaster Identification measures
For Hypotheses H2.1, H2.2, H3.1 and H3.2 Group identification is measured by 2 questions which are two different types of group identification: identification with other audience members and feeling like being in a club with other fans of the broadcaster (Hu et al., 2017; Masayuki Yoshida, Bob Heere, & Brian Gordon, 2015). Broadcaster identification is measured by 4 questions about whether people use Twitch to follow a broadcaster and whether they see them as a model to follow, align with their values or are proud to follow them (Hu, Zhang, & Wang, 2017; Liu, Liao, & Wei, 2015; Shamir, Zakay, Breinin, & Popper, 1998).
Antecedent measures
For Hypotheses H3.1 and H3.2, para-social experience is measured through three questions regarding recruitment and reactions between individual and broadcaster (Hartmann & Goldhoorn, 2011; Hu et al., 2017). Conformity motivation is measured by asking two questions to see whether people the respondent communicates with are also watching Twitch (Chang & Zhu, 2011). Co-experience is measured by one question regarding cognitive communion (sharing thoughts with other members) and two questions regarding resonant contagion (mutual influence on behavior of audience) (Hu et al., 2017; Lim, Cha, Park, Lee, & Kim, 2012). Sense of community is measured using five questions to determine belongingness, needs fulfilment and other indicators (Hilvert-Bruce, Neill, Sjöblom, & Hamari, 2018; Mcmillan & Chavis, 1986; Peterson, Speer, & Mcmillan, 2008).
Support Threshold
Given the results are to be analyzed as correlation of pairwise relationships, support will be calculated by taking the proportion of correlated relationships over total relationships. A hypothesis will be supported if the support is greater than 70%.
Question responses were compared pairwise in this study. There were 38 questions and the results of positive correlations are shown in Tables 2 and 3. There were no negative correlations.
The results for each pairwise comparison is noted in the tables 2 and 3 below, for each hypothesis. The results of the hypotheses involving group identification (H2.2 and H3.2) were split into two because the results were quite different, whereas for broadcaster identification they were aligned across all three measurement questions.
The strength of the pairwise correlations were measured and reported by Qualtrics using p-value, effect size and confidence level of 95%. A correlation is anything with a p value of 0.05 or less. Qualtrics denotes a relationship as subtly positively correlated if it has a p value between 0.05 and approximately 0.01. Anything between 0.01 and 0.00001 is positively correlated and less than 0.00001 is strongly positively correlated. In the tables below, next to each question there is the text of the question, plus quantities of each type of correlated relationship. A subtly positively correlated result is denoted with SPC, a strong correlation with STRONG and positive correlations are either not noted or noted with a PC. The total of correlated relationships over total relationships is also denoted in each cell of the matrix (in brackets and italics) to summarize the overall result and these results are described below.
Table 2 shows the results for H1.1, H1.2, H2.1 and H2.2, and Table 3 shows the results for H3.1 and H3.2.
For H1.1, Table 2 shows 3 of 6 measures of information seeking and entertainment motivation were positively correlated to continuous watching intent.
For H1.2, only 1 of a total 8 responses were positively correlated to continuous watching intent.
For H2.1, 11 of a total 12 responses for information seeking and entertainment motivations were positively correlated to Broadcaster Identification. However, the research also reviewed the positive correlations to Social Motivations for Broadcast Identification and 16 of 24 responses were positively correlated.
For H2.2, where the response was feeling like a group of fans of the broadcaster, 7 of 8 responses for measures of social motivations were positively correlated to Group Identification. In addition, responses for 3 of 6 measures of information seeking and entertainment motivation were positively correlated to Group Identification, which is a different relationship to that posited by H2.2.
For H2.2, where the response was feeling like identifying with the broadcasters followers, 7 of 8 responses for measures of social motivations were positively correlated to Group Identification. In contrast to the Fan Club group identification, only 1 of 6 responses for information seeking and entertainment motivation were positively correlated to Group Identification, which does not support a different relationship to that posited by H2.2.
The results for Hypotheses H3.1 and H3.2 are shown in Table 3, again with H3.2 split for Fans of the Broadcaster and Identifying with other followers.
For H3.1, the antecedent question responses for Broadcaster identification were correlated for para-social experience in 7 of 9 relationships. In addition, sense of community (13/15), conformity motivation (6/6) and co-experience (8/9) relationships were also positively correlated.
For H3.2 for the Club of Fans, there was positively correlation across all relationships, para-social experiences (3/3), sense of community (5/5), conformity motivation (2/2) and co-experience (3/3).
For H3.2 Identifying with other followers group identification, there was positively correlation across almost all relationships, para-social experiences (3/3), sense of community (4/5), conformity motivation (2/2) and co-experience (3/3).
Area
#
H3.1
H.3.2
H3.2
Broadcaster (3)
Group- Club of Fans (1)
Group -identify with followers (1)
Brief Sense of Community
5
fulfill my needs (SPC)+PCI have a say about what goes on x3 People in this Twitch channel are good at influencing each other.I belong in my most watched Twitch channel.(SPC x 2I have a good bond with others in (SPC+ STRONG_ PC)Fulfil my needs (SPC)Good at influencing each other x1 +SPC (13/15)
I have a good bond with others in my most watched Twitch channel. STRONGPeople in this Twitch channel are good at influencing each other.My most watched Twitch channel helps me fulfill my needs.I belong in my most watched Twitch channel. I have a say about what goes on in my most watched Twitch channel.(5/5)
I have a say about what goes on in my most watched Twitch channel.I have a good bond with others in my most watched Twitch channel.People in this Twitch channel are good at influencing each other.I belong in my most watched Twitch channel.(4/5)
Cognitive Community
1
I felt I shared similar thoughts with othe…ence members x 2(2/3)
I felt I shared similar thoughts w(1/1)
I felt I shared similar thoughts(1/1)
Conformity motivation
2
Many people I communicate with watch Twitch.tv x2+SPCOf the people I communicate with regularly; many watch Twitch.tv x2+SPC(6/6)
Many people I communicate with watch Twitch.tvOf the people I communicate with regularly; many watch Twitch.tv.(2/2)
Many people I communicate with watch Twitch.tvSPCOf the people I communicate with regularly; many watch Twitch.tv.(2/2)
Experience of parasocial interaction
3
While I was watching, the broadcaster knew that I reacted to them (SPC x 2+ PC)While I was watching, the broadcaster reacted to what I said or did x 3While I was watching, the broadcaster knew I paid attention to them.(7/9)
While I was watching, the broadcaster knew that I reacted to themWhile I was watching, the broadcaster reacted to what I said or did.While I was watching, the broadcaster knew I paid attention to them.(3/3)
While I was watching, the broadcaster reacted to what I said or did.(SPC)While I was watching, the broadcaster knew that I reacted to them.(3/3)
Resonant contagion
2
My behavior was influenced by others in th…dience group x 2+SPCMy behavior influenced others in this audience group x3(6/6)
My behavior influenced others in this audience group of my most watched Twitch channel.My behavior was influenced by othersSTRONG(2/2)
My behavior was influenced by othersMy behavior influenced others(2/2)
The threshold for support is 75% of relationships being correlated.
As support for H1.1 Use of Twitch for information seeking and entertainment motivations are positively correlated with intention of continuation of engagement was 50%, this hypothesis is not supported.
Support for H1.2 1 Use of Twitch for social motivations are positively correlated with intention of continuation of engagement was 16% (1 in 8), this hypothesis is not supported.
Support for H2.1 Use of Twitch for information seeking and entertainment motivations is positively correlated with Broadcaster Identification is 92% (11 in 12), so this hypothesis is supported.
Support for H2.2 Use of Twitch for social motivations is positively correlated with Group Identification where participants felt like a group of fans of the broadcaster was 88% (7 in 8), so this hypothesis is supported. The results for this group using Twitch for information seeking and entertainment motivations were 50% (3 in 6) so do not meet the threshold.
Support for H2.2 Use of Twitch for social motivations is positively correlated with Group Identification where participants identified with other followers of the broadcaster was 88% (7 in 8), so this hypothesis is supported. The results for this group using Twitch for information seeking and entertainment motivations were 16% (1 in 6) so do not meet the threshold.
Support for H3.1 Para-social experience is positively corelated to Broadcaster Identification through Twitch was 78% (7 in 9), so this hypothesis is supported.
Support for H3.2 Conformity Motivation, Sense of Community and Co-experience is positively correlated to Group Identification where participants felt like a group of fans of the broadcaster was 100% (13 in 13), so this hypothesis is supported.
Support for H3.2 Conformity Motivation, Sense of Community and Co-experience is positively correlated to Group Identification where participants identified with other followers of the broadcaster was 92% (12 in 13), so this hypothesis is supported.
Implications
Unlike other research, a statistically significant relationship could not be found in this survey for watching continuation intention, for neither information seeking, entertainment or social motivations.
As hypothesized in this research, people who identify with Broadcasters use Twitch for entertainment and information seeking purposes, and those who identify with Groups use Twitch to gratify social motivations.
Unlike Hu et al (Hu et al., 2017), this research found that users who identify with Groups and with the Broadcaster all experience para-social feelings towards the Broadcaster, and also a sense of community with other members, are driven by conformity motivations in their use of the platform, and share a co-experience of Twitch with other users in their group also.
This was a very small sample, so the results are exploratory rather than able to be generalized to a wider population, but it is clear that the respondents of this survey who are users of Twitch have strong social reasons for being on the platform.
Limitations and future directions
The analysis of the contribution of each survey question to the underlying phenomena being measured was very rudimentary i.e based on the proportion of correlated relationships to total relationships. This was due to the limitations of Qualtrics and the researcher’s abilities being limited to that system. Regression analysis was attempted for correlated variables, however the explanatory power was very limited because the sample size was so small. In additional, Qualtrics is unable to conduct contributory factor analysis, so this research relied upon the relationships establishing by the research papers from which the survey questions were drawn (see Table 1). However a lot of these relationships would have been nullified as this is a different sample, and some questions were removed from this survey.
Further analysis could be conducted using a more advanced statistical software package and a larger sample size to overcome these issues.
Conclusions
This small survey of 87 participants could not establish a relationship between psychological motivations (information seeking, entertainment or social) and watching continuance intention. However, it did support the hypothesis and align with past research that those users who have online social identities aligned to the broadcaster do use the platform for information seeking and entertainment, and those who align their identities with groups of other audience members use Twitch for social motivations. A novel finding of this research was that whether or not people identified with Group or Broadcasters, they all experience para-social feelings towards the Broadcaster, and also a sense of community with other members, are driven by conformity motivations in their use of the platform, and share a co-experience of Twitch with other users in their group also.
References
Chang, Y. P., & Zhu, D. H. (2011). Understanding social networking sites adoption in China: A comparison of pre-adoption and post-adoption. Computers in Human Behavior, 27(5), 1840–1848. https://doi.org/10.1016/j.chb.2011.04.006
Chiu, C.-M., Hsu, M.-H., & Wang, E. T. G. (2006). Understanding knowledge sharing in virtual communities: An integration of social capital and social cognitive theories. Decision Support Systems, 42(3), 1872–1888. https://doi.org/10.1016/j.dss.2006.04.001
Choe, H. (2019). Eating together multimodally: Collaborative eating in mukbang, a Korean livestream of eating. Language in Society, 48(2), 171–208. https://doi.org/10.1017/S0047404518001355
Ford, C., Gardner, D., Horgan, L., & Liu, C. (2017). Chat Speed OP : Practices of Coherence in Massive Twitch Chat. 12.
Hartmann, T., & Goldhoorn, C. (2011). Horton and Wohl Revisited: Exploring Viewers’ Experience of Parasocial Interaction. Journal of Communication, 61(6), 1104–1121. https://doi.org/10.1111/j.1460-2466.2011.01595.x
Hilvert-Bruce, Z., Neill, J. T., Sjöblom, M., & Hamari, J. (2018). Social motivations of live-streaming viewer engagement on Twitch. Computers in Human Behavior, 84, 58–67. https://doi.org/10.1016/j.chb.2018.02.013
Hu, M., Zhang, M., & Wang, Y. (2017). Why do audiences choose to keep watching on live video streaming platforms? An explanation of dual identification framework. Computers in Human Behavior, 75, 594–606. https://doi.org/10.1016/j.chb.2017.06.006
Jenkins, H. (2006). Fans, bloggers, and gamers exploring participatory culture. New York: New York University Press.
Kang, Y. S., Hong, S., & Lee, H. (2009). Exploring continued online service usage behavior: The roles of self-image congruity and regret. Computers in Human Behavior, 25(1), 111–122. https://doi.org/10.1016/j.chb.2008.07.009
Lim, S., Cha, S. Y., Park, C., Lee, I., & Kim, J. (2012). Getting closer and experiencing together: Antecedents and consequences of psychological distance in social media-enhanced real-time streaming video. Computers in Human Behavior, 28(4), 1365–1378. https://doi.org/10.1016/j.chb.2012.02.022
Liu, S., Liao, J., & Wei, H. (2015). Authentic Leadership and Whistleblowing: Mediating Roles of Psychological Safety and Personal Identification. Journal of Business Ethics, 131(1), 107–119. https://doi.org/10.1007/s10551-014-2271-z
Masayuki Yoshida, Bob Heere, & Brian Gordon. (2015). Predicting Behavioral Loyalty through Community: Why Other Fans Are More Important Than Our Own Intentions, Our Satisfaction, and the Team Itself. Journal of Sport Management, 29(3), 318–333. https://doi.org/10.1123/jsm.2013-0306
Mcmillan, D., & Chavis. (1986). Sense of community: A definition and theory. 18.
Pendry, L. F., & Salvatore, J. (2015). Individual and social benefits of online discussion forums. Computers in Human Behavior, 50, 211–220. https://doi.org/10.1016/j.chb.2015.03.067
Peterson, N., Speer, P., & Mcmillan, D. (2008). Validation of a Brief Sense of Communtiy Scale: Confirmation of the Principal Theory of Sense of Community. Journal of Community Psychology, 36, 61–73. https://doi.org/10.1002/jcop.20217
Postmes, T., Spears, R., & Lea, M. (1998). Breaching or Building Social Boundaries?: SIDE-Effects of Computer-Mediated Communication. Communication Research, 25(6), 689–715. https://doi.org/10.1177/009365098025006006
Shamir, B., Zakay, E., Breinin, E., & Popper, M. (1998). Correlates of Charismatic Leader Behavior in Military Units: Subordinates’ Attitudes, Unit Characteristics, and Superiors’ Appraisals of Leader Performance. Academy of Management Journal, 41(4), 387. https://doi.org/10.2307/257080
Tajfel, & Turner. (1979). An integrative theory of intergroup conflict.
WALTHER, J. B. (1996). Computer-Mediated Communication: Impersonal, Interpersonal, and Hyperpersonal Interaction. Communication Research, 23(1), 3–43. https://doi.org/10.1177/009365096023001001
Xiao, H., Li, W., Cao, X., & Tang, Z. (2012). The Online Social Networks on Knowledge Exchange: Online Social Identity, Social Tie and Culture Orientation. Journal of Global Information Technology Management, 15(2), 4–24. https://doi.org/10.1080/1097198X.2012.11082753
(Hilvert-Bruce et al., 2018; Mcmillan & Chavis, 1986; Peterson et al., 2008)
Removed
Brief Sense of Community
I have a say about what goes on in my Twitch channel.
(Hilvert-Bruce et al., 2018; Mcmillan & Chavis, 1986; Peterson et al., 2008)
No
Brief Sense of Community
People in this Twitch channel are good at influencing each other.
(Hilvert-Bruce et al., 2018; Mcmillan & Chavis, 1986; Peterson et al., 2008)
No
Brief Sense of Community
I feel connected to this Twitch channel.
(Hilvert-Bruce et al., 2018; Mcmillan & Chavis, 1986; Peterson et al., 2008)
Removed
Brief Sense of Community
I have a good bond with others in this Twitch channel.
(Hilvert-Bruce et al., 2018; Mcmillan & Chavis, 1986; Peterson et al., 2008)
no
Conformity motivation
Many people I communicate with watch Twitch.
(Chang & Zhu, 2011)
No
Conformity motivation
The people I communicate with will continue to watch Twitch.
(Chang & Zhu, 2011)
Removed
Conformity motivation
Of the people I communicate with regularly; many watch Twitch.
(Chang & Zhu, 2011)
No
Cognitive Communion
I felt I shared similar thoughts with other audience members.
(Hu et al., 2017; Lim et al., 2012)
No
Cognitive Communion
I felt my knowledge was shared with other audience members.
(Hu et al., 2017; Lim et al., 2012)
Removed
Cognitive Communion
I felt I shared the same perspective as other audience members.
(Hu et al., 2017; Lim et al., 2012)
Removed
Continuous watching intention (CWI)
I intend to continue to watch Twitch.tv within the next two months.
(Chang & Zhu, 2011; Hu et al., 2017; Kang, Hong, & Lee, 2009)
No
Continuous watching intention (CWI)
I intend to continue following the broadcaster rather than discontinuance.
(Hu et al., 2017; Kang et al., 2009)
Removed
Continuous watching intention (CWI)
I intend to continue watching the broadcaster’s channel rather than other alternatives.
(Hu et al., 2017; Kang et al., 2009)
No
Entertainment Motivation
I watch Twitch.tv to pass the time.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
Removed
Entertainment Motivation
I watch Twitch.tv to entertain myself with games.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
Removed
Entertainment Motivation
I watch Twitch.tv for fun.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
No
Experience of parasocial interaction
While I was watching, the broadcaster knew I paid attention to them.
(Hartmann & Goldhoorn, 2011; Hu et al., 2017)
No
Experience of parasocial interaction
While I was watching, the broadcaster knew that I reacted to them.
(Hartmann & Goldhoorn, 2011; Hu et al., 2017)
No
Experience of parasocial interaction
While I was watching, the broadcaster reacted to what I said or did.
(Hartmann & Goldhoorn, 2011; Hu et al., 2017)
No
Channel size preference
Please estimate the number of viewers who are typically in the Twitch channel(s) you spend the most time viewing. Small 500 or less Large 501 to 10000 Very Large over 10000
(Hilvert-Bruce et al., 2018)
No
My friends (in real life) and I like to watch the same channels.
Me
Removed
My friends (in real life) and I like to chat in stream chats on Twitch.tv.
Me
Removed
Meeting new people
I meet new people in stream chat rooms.
(Chang & Zhu, 2011)
No
I like to follow certain broadcasters’ channels.
Me
No
I like to follow channels related to a certain game.
Me
No
Group identification (GRI)
I really identify with people who follow the broadcaster.
(Hu et al., 2017; Masayuki Yoshida, Bob Heere, & Brian Gordon, 2015)
No
Group identification (GRI)
I feel like I belong to a club with other fans of the broadcaster.
(Hu et al., 2017; Masayuki Yoshida et al., 2015)
No
Group identification (GRI)
The broadcaster is supported by people like me.
(Hu et al., 2017; Masayuki Yoshida et al., 2015)
Removed
Information motivation (IΜ)
I watch Twitch.tv to learn about things I don’t know.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
No
Information motivation (IΜ)
I watch Twitch.tv to search for information I need.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
Removed
Information motivation (IΜ)
I watch Twitch.tv to keep up to date.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
Removed
Information motivation (IΜ)
I watch Twitch.tv get useful information.
(Chang & Zhu, 2011; Hilvert-Bruce et al., 2018)
No
Online Social Identity
I know the screen names of others in this stream chat room.
(Postmes et al., 1998; WALTHER, 1996; Xiao et al., 2012)
No
Online Social Identity
I know the real names of others in this stream chat room.
(Postmes et al., 1998; WALTHER, 1996; Xiao et al., 2012)
No
Online Social Identity
I know the personalities of others in this stream chat room.
(Postmes et al., 1998; WALTHER, 1996; Xiao et al., 2012)
No
Online Social Identity
Others in this stream chat room know my screen name.
(Postmes et al., 1998; WALTHER, 1996; Xiao et al., 2012)
No
Online Social Identity
Others in this stream chat room know my real name.
(Postmes et al., 1998; WALTHER, 1996; Xiao et al., 2012)
No
Online Social Identity
Others in this stream chat room know my personality.
(Postmes et al., 1998; WALTHER, 1996; Xiao et al., 2012)
No
Online Social Tie
I frequently interact with others in the Twitch community.
(Xiao et al., 2012)
No Modified from a free text question
Engagement indicator
I frequently watch Twitch.tv.
(Hilvert-Bruce et al., 2018)
No Modified from a free text question
Resonant contagion (REC)
My behavior was influenced by others in this audience group.
(Hu et al., 2017; Lim et al., 2012)
No
Resonant contagion (REC)
My behavior influenced others in this audience group.
(Hu et al., 2017; Lim et al., 2012)
No
Resonant contagion (REC)
Our audience group agreed upon similar opinions.
(Hu et al., 2017; Lim et al., 2012)
Removed
Our audience group engages in ASCII art chat.
ME
Removed
Our audience group engages in copypasta chat.
ME
No
What is your age? Under 18 18 – 24 25 – 34 35 – 44 45 – 54 55 – 64 65 – 74 Over 74
ME
No
55. What is your gender? Female Male Other Prefer not to say